
Com a atual expansão da internet, diversas ferramentas têm sido implementadas por desenvolvedores para executar automaticamente tarefas que sejam consideradas chatas ou até mesmo repetitivas. Estas ferramentas, conhecidas como Bots, na maioria das vezes apresentam propósito útil e não visam prejudicar serviços alheios. Entretanto, existem Bots com características maliciosas que executam tarefas de forma exagerada, com a intenção de danificar operações de um serviço alvo.
Neste artigo, falaremos sobre os Good Bots e Bad Bots, comentando exemplos de Bots que podem ser considerados maliciosos por estarem atuando agressivamente em serviços espalhados na Internet.
Good Bots e Bad Bots
Um Bot nada mais é do que um software que atua realizando automaticamente alguma tarefa específica. Desta maneira, Bots podem estar configurados para executar a mesma função de dezenas a milhares de vezes durante um único dia, mesmo sem a intervenção humana. Há estudos que indicam que mais de 42% de todo o tráfego da internet é realizado por Bots.
Dentre as diversas tarefas que um Bot pode exercer na rede, existem aquelas destinadas a automatizar tarefas sem propósito malicioso, como verificar disponibilidade de serviços Web, realizar Web Crawler visando coleta de informações e indexar páginas web para motores de busca. Sendo assim, esses Bots tendem a ser considerados como “Good Bots”, já que não há intenção de realizar prejuízo a serviço de terceiros.
Entretanto, como a diferença entre o remédio e o veneno é a dosagem, Good Bots que por ventura exerçam suas funções de forma exagerada talvez possam prejudicar serviços em forma de ataques de DDoS ou DoS não intencional. Isso acontece pois um Good Bot mal configurado pode efetuar um grande volume de requisições em serviços, causando assim uma possível indisponibilidade e transformando-se em um Bad Bot. Nesses casos, coibir a atuação desses Bots que exageram na execução do seu trabalho torna-se uma medida necessária.
Diferentemente dos Good Bots que se tornam Bad Bots não intencionalmente, existem Bots que são implementados com propósito malicioso desde o princípio. Tais Bots normalmente são criados por criminosos para exercer atividades ilegais.
Podemos citar os Scrapers como exemplos de Bad Bots. Scrapers normalmente são responsáveis pelo rastreamento e varredura de websites no objetivo de furtar informação. Na maioria das vezes, a informação furtada é alocada em um site fraudulento para que motores de busca indexem a página falsa antes da original. Assim, usuários podem ser direcionados a página falsa e sofrerem outros tipos de ataques, como phishing por exemplo.
Reconhecendo um Bot
A existência de uma grande quantidade de Bad Bots comumente motiva que administradores de sistemas se sintam inclinados a bloquear todo e qualquer Bot, seja ele malicioso ou não. Entretanto, visto que há casos em que Good Bots podem ser úteis devido a regras de negócio da aplicação – vide Bots do Google que indexam páginas web para retornar em seu motor de busca – realizar o bloqueio indiscriminatório de Bots acaba sendo um contexto proibitivo.
Nesses casos, é necessário que os administradores consigam primeiramente reconhecer um Bot e, após isso, identificar se é necessário realizar um bloqueio deste ou não. Então veremos neste tópico algumas formas de identificá-los.
Atualmente, é comum que Bots se comuniquem com serviços web mediante requisições HTTP. O protocolo HTTP (Hypertext Transfer Protocol) atua na camada de aplicação do modelo OSI por meio de requisição-resposta entre cliente e servidor. Com isso, a forma mais prática de identificar Bots é analisar o corpo da requisição em busca de algum dado indicativo de que o autor é de fato um Bot.
Vamos analisar o seguinte cabeçalho (header) de uma requisição HTTP retirada dos sistemas da XLabs Security:
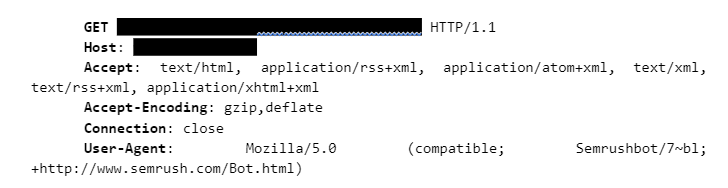
Por meio do cabeçalho da requisição HTTP acima, observamos que existem diversos campos que carregam informações a respeito da requisição em si, a saber: Host, Accept, Accept-Encoding, etc. Um desses campos, trata-se do User-Agent, que normalmente indica qual foi o agente responsável por criar de fato a requisição em questão. Podemos observar que o campo “User-Agent” contém a seguinte a palavra “Semrushbot”, este é um Bot de pesquisa para descobrir se houveram atualizações em determinado website. Não sendo um Bot malicioso, cabe ao administrador entender se tais requisições devem ser bloqueadas.
Agora vamos analisar outro exemplo. No header abaixo, novamente observamos um cabeçalho de requisição HTTP. Observa-se que o campo User-Agent contém a palavra MJ12bot que é um Bot focado em mapear a relação entre websites. Da mesma forma que ocorre com o SemrushBot, administradores que definem se concederão resposta a requisição MJ12bot ou não.

Através dos exemplos, conseguimos observar que uma das principais formas de se legitimar um Bot é analisando o campo User-Agent da requisição, visto que Good Bots comumente utilizam este dado como identificador.
Entretanto, há a existência de Bad Bots que fraudam a informação User-Agent na tentativa de se passar por um usuário normal. Nesses casos, os administradores necessitam recorrer a outros métodos de identificação analisando outros campos da requisição HTTP em busca de alguma assinatura que permita a identificação de um possível Bad Bot.
Existem projetos open-sources como o matomo-org/referrer-spam-list¹ que apresenta uma lista de hosts conhecidos por exercerem papel de Bad Bots na rede. Assim, administradores podem usufruir deste tipo de conhecimento público para identificar Bots maliciosos e decidir se irão responder às requisições desses hosts ou não.
¹https://github.com/matomo-org/referrer-spam-list
Exemplos de Good e Bad Boots
Vamos observar agora alguns exemplos de Good Bots e Bad Bots.
Good Bots
Bot de direitos autorais: Tem o objetivo de rastrear plataformas e sites que possam conter assunto que violem a lei de direitos autorais. Bots dessa categoria podem ser operados por qualquer pessoa ou corporação que tenha conteúdo protegido pela lei referente. Esses Bots conseguem procurar textos, músicas, imagens e também vídeos copiados.
Bot de assistente: Programas mais avançados que utilizam uma AI (Artificial Intelligence) utilizam a busca de dados automaticamente, sendo assim, são considerados Bots. Atualmente temos como exemplos desse tipo os sistemas da Alexa, Siri, Google Assistente entre outros.
Bot comercial: São utilizados por corporações comerciais que investigam a rede para ter acesso às informações do mercado. Estes Bots podem ser utilizados em pesquisas de público alvo, uma vez que monitoram relatórios de notícias ou, até mesmo, analisando consumidores e seus comportamentos.
Bots de feed: Vasculham a internet em busca de assuntos importantes para adicionar a um feed de notícias específicos.
Bots de monitoramento de sites: Monitoram métricas dos websites como situação de backlinks ou intermitências no sistema. Encontrando alguma irregularidade emitem alertas aos administradores do sistema.
Bots de pesquisa: Conhecidos também por web crawlers ou spiders, seu papel é buscar e conferir o conteúdo na rede, organizando o material para que possa ser indexado em formas de resultados de motores de busca.
ChatBots: Possuem capacidade de interação com seres humanos.
Exemplos de Bad Bots
Bots de DDoS: São bots coordenados que, por meio de um volume muito grande de requisições sobrecarregam um determinado website. Criminosos utilizam essa técnica para causar indisponibilidade de serviço.
Bots de Web Scraping: Extraem exageradamente os dados de um website, fazendo uma “raspagem de conteúdo”, e assim direcionam o conteúdo para fins maliciosos.
Bots de Comment Spam: Abusam de formulários encontrados em sites para postar conteúdo não solicitado.
Bots de Spamdexing: Responsáveis por alterar a relevância de um determinado website em motores de busca.
Coibindo Ações de Bots
Existem diversas formas de se coibir a ação de Bots, veremos aqui então algumas delas.
Arquivo robots.txt
A principal forma de limitar a ação de Bots é por meio do arquivo robots.txt. Trata-se de um arquivo especial situado no diretório da aplicação Web que delimita por meio de diretivas quais as permissões e bloqueios de determinados User-Agents, também possibilitando definir o delay (tempo) mínimo exigido entre requisições.
Segue um exemplo de formatação do arquivo roBots.txt:
User-agent: *
Allow: /
No exemplo acima, por meio do asterisco presente na diretiva User-Agent e da “/” presente em Allow, define-se que todo e qualquer agente pode efetuar requisições em qualquer caminho da aplicação Web.
User-agent: MJ12Bot
Disallow: /
No exemplo acima, por meio da diretiva Disallow o Bot MJ12bot está proibido de fazer requisições em qualquer caminho do Website.
Outra diretiva permitida no robots.txt é a “Craw-delay”. Essa tem por objetivo retardar a ação do Bot de modo em que o mesmo só consiga fazer uma nova requisição depois de um tempo predeterminado. Assim, determina-se que os Bots não executem tantas requisições por segundo.
User-agent: SemrushBot
Disallow: /Craw-delay: 5
No exemplo de configuração de robots.txt acima, o Bot SemrushBot pode efetuar requisições no website a cada 5 segundos devido a definição da diretiva Craw-delay.
Rate Limit
Outra forma de evitar o bloqueio de uma Good Bot e manter o bloqueio de Bad Bots, é a utilização de ferramentas de Rate Limit, que são capazes de analisar tráfego por meio da investigação de logs de acesso, pontuando e mitigando a ação de Bots com comportamento anômalo. O mecanismo de Rate Limit comumente já está inserido em serviços de CDN, comentados a seguir.
CDN (Content Delivery Network)
Aplicar um serviço de WAF (web application firewall) com CDN também pode ser uma alternativa viável para o bloqueio de Bots. Isso ocorre pois muitos serviços de WAF/CDN como o da XLabs Security abstrai ao administrador da aplicação diversos mecanismos de detecção e mitigação de Bad Bots.
Mecanismo de Captcha
Limitar o acesso do website a mecanismos de Captcha como o reCAPTCHA da Google pode reduzir significativamente a ação de Bots. Isto ocorre, pois, com esses mecanismos uma ação humana de reconhecimento de padrões é exigida antes de permitir o acesso às informações contidas nos sites.
Conclusão
Com a grande quantidade de Bots trafegando pela Internet, é necessário que administradores de websites sejam obrigados a definir como lidar com eles, sejam bem intencionados ou não.
Apesar de existirem formas de reconhecer o Bot e a partir disso restringir a comunicação com o mesmo, existem Bots que tentam mascarar sua função buscando se passar por um usuário convencional. Esses Bots, se não identificados, podem comprometer o funcionamento de uma aplicação através de quantidades exageradas de requisições ou, então, através do sequestro de dados.
Nesse contexto, é importante a utilização de ferramentas especializadas em detectar e mitigar a ação de todo e qualquer tipo de Bot, como por exemplo a CDN da XLabs Security, que é capaz de identificar e tratar os Bots antes que eles causem qualquer prejuízo ao site.
Quer saber mais sobre a CDN da XLabs? Fale agora mesmo com nossos especialistas!




